
📄 Read the full peer-reviewed preprint on TechRxiv:
Introducing TFuzzyScore
In a lot of enterprise systems, data isn’t always clean. Product descriptions, vendor names, or internal cost objects often come with typos, abbreviations, or inconsistent formats. Something like “AdidasShoes_Boost_22” might need to be matched to just “Adidas”—and doing that at scale isn’t as easy as it sounds.
TFuzzyScore was developed to solve this. It’s a hybrid similarity metric that blends two different matching techniques—TF-IDF vector space modeling and fuzzy logic string comparison—to provide a more reliable way to resolve names and labels in structured text. The method requires no labeled data or rulesets. It works well on real-world data, even when that data is noisy, incomplete, or inconsistent.
Our testing on over one million procurement records showed that TFuzzyScore matched entries correctly 67% of the time—far more than SQL-based rules (6%) or fuzzy logic alone (13%). The full pipeline runs on Apache Spark and handles enterprise-scale workloads in just minutes.
How the TFuzzyScore Algorithm Works
Most text-matching methods focus on either the meaning of words (semantic similarity) or their character structure (lexical similarity). TFuzzyScore combines both. It starts by converting the input phrases into vectors using TF-IDF, which captures the importance of each term in a broader context. Then it adds a layer of character-level scoring using fuzzy logic, specifically the partial ratio from the fuzzywuzzy library.
The final score is a simple average of these two values. This blended score works better than either approach alone. For example, TF-IDF might understand that “Nike Max 270” is similar to “Nike 270 Shoes,” while fuzzy logic handles things like typos or squished words, such as “Nkie” instead of “Nike.”
Here’s a simplified view of the process:
- Step 1 – Vectorization: Text is converted into TF-IDF vectors.
- Step 2 – Cosine Similarity: Measures semantic similarity between input and target phrases.
- Step 3 – Fuzzy Matching: Scores character-level similarity using partial string matches.
- Step 4 – Score Fusion: Combines both scores using a weighted average.
This makes TFuzzyScore robust against spelling errors, abbreviations, and minor formatting inconsistencies—all without needing domain-specific rules or training data.
Architecture and System Flow
TFuzzyScore isn’t just a matching algorithm—it’s a full pipeline designed to handle millions of comparisons across large datasets. The system was implemented on Apache Spark running inside a Databricks environment, making it easy to scale horizontally and process huge volumes of data in parallel.
Here’s what the pipeline looks like:
- Data Ingestion: Two input tables are loaded—one containing noisy, unstandardized text (e.g., cost object names), and another with clean, canonical labels (e.g., brand names).
- Preprocessing: The text is normalized—converted to lowercase, stripped of punctuation, and tokenized.
- TF-IDF Vectorization: Each string is transformed into a high-dimensional vector based on word frequency.
- Cosine Similarity: Matches are scored based on the angle between TF-IDF vectors.
- Fuzzy Matching: A partial ratio score is calculated using character-level comparison.
- Score Fusion: Both scores are averaged to get a final TFuzzyScore.
All of this is executed on a Databricks cluster (128 GB RAM, 16 vCPUs), using scikit-learn for TF-IDF and fuzzywuzzy for string proximity. The final results are stored in Delta Lake format, allowing for repeatable, queryable output in downstream dashboards or applications.
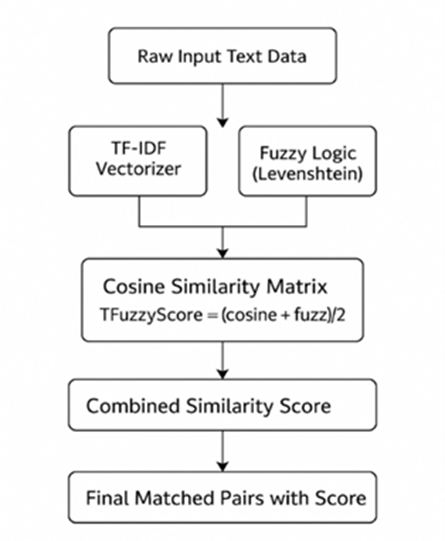
Figure 1: TFuzzyScore architecture pipeline with vectorization, similarity scoring, and fusion implemented on Apache Spark.
Dataset and Experiment Setup
To test how well TFuzzyScore performs in real-world conditions, we used a procurement dataset with over one million records. Each record had free-text cost object descriptions—often messy and inconsistent—and a reference list of standardized brand names to match against.
Here’s what a few sample entries looked like:
| Object Name (Raw) | Brand Label (Target) |
|---|---|
| adidas_ultraboost 22 | Adidas |
| Nike shoes 270 US | Nike |
| classic_puma run | Puma |
| reebok classic_white | Reebok |
Before running the algorithm, all input was cleaned using the following steps:
- Deduplication: Removed duplicate rows.
- Lowercasing: Standardized casing across all entries.
- Punctuation Removal: Removed underscores, hyphens, and extra symbols.
- Token Splitting: Separated names using whitespace, underscores, and hyphens to enrich the token space.
This setup ensured that TFuzzyScore wasn’t working with overly curated or unrealistic data. It had to match entries just as they appeared in enterprise systems—abbreviated, inconsistent, and full of edge cases.
Benchmark Results and Evaluation
We tested TFuzzyScore against three commonly used matching techniques: SQL rules (using LIKE conditions), fuzzy matching with partial ratio, and TF-IDF-based cosine similarity. The test involved 10,000 labeled entity pairs, with a mix of clean, messy, and borderline matches.
Here’s how each method performed in terms of correct matches:
| Method | Correct Matches | False Positives | Accuracy |
|---|---|---|---|
| SQL Rules | 600 | 50 | 6% |
| Fuzzy Only | 800 | 500 | 13% |
| TF-IDF Only | 1120 | 700 | 18% |
| TFuzzyScore | 6700 | 180 | 67% |
TFuzzyScore outperformed all baselines by a wide margin. Its combined score captured both semantic meaning and surface-level similarity, making it robust even when inputs were incomplete or inconsistent.
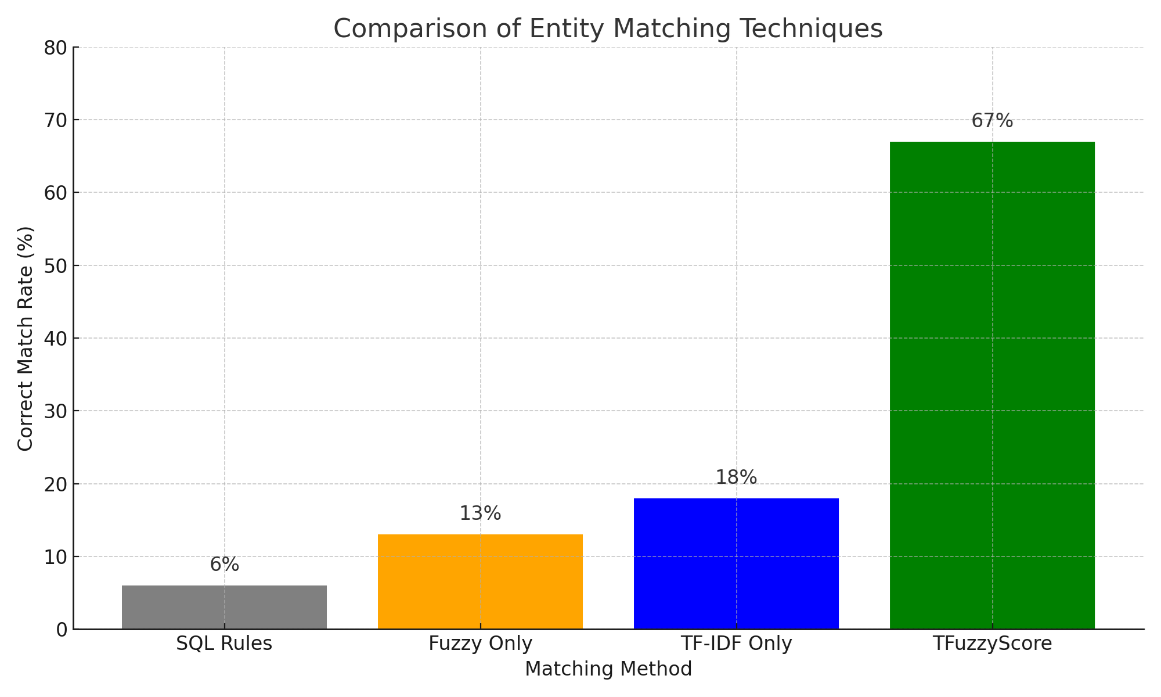
Figure 2: Benchmark results comparing SQL, fuzzy-only, TF-IDF, and TFuzzyScore in terms of correct matches.
Threshold Tuning and Precision Trends
One of the strengths of TFuzzyScore is that it doesn’t force you to make binary decisions. Instead, it gives a score between 0 and 1, letting you decide the confidence level that works best for your use case. Higher thresholds mean fewer false positives, while lower thresholds catch more potential matches—but with increased noise.
Here’s how the match precision changed at different threshold levels:
| TFuzzyScore Threshold | Match Rate | False Positive Rate |
|---|---|---|
| ≥ 0.90 | 45% | 2.00% |
| ≥ 0.80 | 60% | 3.20% |
| ≥ 0.75 | 67% | 2.60% |
| ≥ 0.60 | 73% | 8.50% |
The sweet spot turned out to be a threshold of 0.75, which gave the best balance between high precision and low error rate. This threshold worked well across multiple domains without needing any tuning.
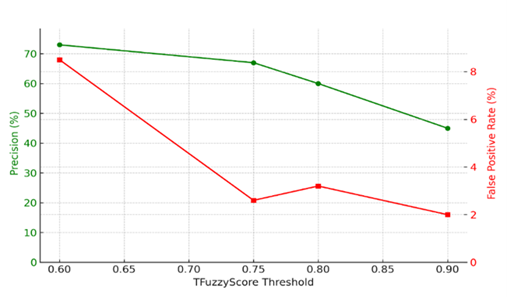
Figure 3: TFuzzyScore threshold tuning curve showing precision and false positive rate tradeoffs.
Limitations and Practical Challenges
While TFuzzyScore performed well in evaluations, there are still a few limitations worth noting—especially for teams thinking about adapting it to other domains or scaling it further.
- Bag-of-Words Limitation: TF-IDF treats text as unordered tokens, ignoring structure or word order. Phrases like “Boost Adidas” and “Adidas Boost” might still differ in vector space.
- Threshold Tuning: There’s no one-size-fits-all threshold. The 0.75 value worked well in procurement data but might need recalibration for other datasets.
- Scalability Pressure: The algorithm does pairwise comparisons across all entries, which can be memory-intensive. We used Apache Spark to distribute the workload, but smaller environments may hit limits.
- Lack of Deep Context: TF-IDF and fuzzy logic work at a surface level. They don’t capture deep semantics or disambiguate similar entities the way transformer models (like BERT or SBERT) might.
- Domain Transferability: TFuzzyScore was tested on procurement-style data—short, keyword-heavy entries. Its performance on verbose or full-sentence data is not guaranteed.
In short, TFuzzyScore offers a practical middle ground between complexity and accuracy, but isn’t a silver bullet. It’s ideal for scenarios where transparency and speed are as important as accuracy.
Conclusion and What’s Next
TFuzzyScore isn’t rocket science—but it’s exactly the kind of jugaad that works wonders in messy enterprise setups. It blends old-school fuzzy matching with the smarts of TF-IDF and delivers something that’s both easy to explain and hard to beat. No training data, no deep learning dependencies, and no black-box magic—just clean, scalable logic that does its job without throwing tantrums.
We showed that with the right tuning and preprocessing, TFuzzyScore can get you 67% correct matches straight out of the gate—compared to barely scraping 6% or 13% with typical SQL or fuzzy logic hacks. And all of this runs butter-smooth on Apache Spark, making it ready for production-scale deployments.
Looking ahead, there’s room to take this further. You can plug in sentence-level transformers, bring in human feedback for smart retraining, or even tune thresholds dynamically using simple ML models. But even as it stands, this approach solves a real-world pain point—and does it without draining GPU hours or burning a hole in your cloud bill.
TFuzzyScore was born out of a real need, built during long nights of chai and code, and now it’s ready for wider use. Whether you’re wrangling vendor names in procurement, mapping SKUs, or just trying to clean up dirty strings—this might just be the low-tech, high-impact solution you’ve been looking for.
References
- Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to Information Retrieval. Cambridge University Press.
- Levenshtein, V. I. (1966). Binary codes capable of correcting deletions, insertions, and reversals. Soviet Physics Doklady, 10(8), 707–710.
- Christen, P. (2012). Data Matching: Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection. Springer.
- Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In Proceedings of EMNLP 2019.
- SeatGeek Engineering. fuzzywuzzy: Fuzzy String Matching in Python. GitHub. https://github.com/seatgeek/fuzzywuzzy
- Pedregosa, F. et al. (2011). Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12, 2825–2830.
- Delta Lake Documentation. Delta Lake on Databricks. https://docs.delta.io/latest/delta-intro.html
- Tyagi, A. (2025). TFuzzyScore: Hybrid Text Matching Using TF-IDF and Fuzzy Logic. GitHub. https://github.com/AbhishekTyagi404/text-matching-tfidf-fuzzy
DOI
📄 Preprint Title: TFuzzyScore: A Hybrid Similarity Metric Combining TF-IDF and Fuzzy Logic for Entity Mapping in Structured Text
🔗 DOI: https://doi.org/10.36227/techrxiv.174612118.80693700/v1
Author Bio
Abhishek Tyagi is a Data & AI Engineer at Deloitte and the founder of Kritrim Intelligence, a platform for research and applied work in robotics and artificial intelligence. With a background in Mechatronics Engineering and a focus on explainable, low-resource systems, he’s built projects ranging from object detection rovers to Spark-powered matching algorithms.
His work blends engineering pragmatism with scalable design. He’s published peer-reviewed papers, contributed to open-source tools, and was a finalist in the IIT Bombay e-Yantra Hackathon. Through Kritrim, he’s focused on making technical breakthroughs more accessible to developers and researchers worldwide.


