
Abstract
Large-scale data pipelines, especially those built on Delta Lake and Spark SQL, require robust mechanisms for null-checking, deduplication, and handling diverse data granularities across multiple ingestion passes. This article presents a novel approach to unify passes with varying granularities, consolidate them efficiently, and apply EXCEPT ALL logic for deduplication before final merging. Our strategy significantly reduces shuffle overhead and ensures high data integrity and transformation fidelity.
1. Introduction
Data pipelines processing upwards of 750 million records often suffer performance hits due to redundant transformations, excessive joins, and multi-pass logic inconsistencies. This becomes more complex when working with datasets like PurchaseInvoiceDetail and LogisticsShipment, where various passes contain the same data in different granularities.
To address this, we propose:
- Granularity Alignment via Union
- Staging using Temporary Delta Tables
- Pre-Merge Deduplication using EXCEPT ALL
1.1 Understanding “Pass” in Data Pipelines
In this context, a “pass” refers to an individual execution or ingestion of data through a pipeline. Each pass represents a distinct layer of data derived from different business logic or upstream sources.
There are typically multiple passes in production pipelines, each differing by:
- Granularity: One may contain raw transaction-level data, another aggregated metrics.
- Source: From ERP systems, forecasting tools, or manual uploads.
- Transformation Scope: Ranging from simple filtering to deep aggregation.
To maintain data consistency while improving performance, these passes must be aligned, unioned, and deduplicated appropriately before merging into the main Delta table.
2. Problem Statement
Common challenges include:
- Inconsistent granularity across passes
- Multiple aggregation layers causing shuffle bottlenecks
- Traditional deduplication (ROW_NUMBER, DISTINCT) is compute-heavy
- Final merge stages often introduce delay and complexity
3. Solution Overview
Our approach involves:
- Granularity Alignment: Union same-level passes before merging.
- Temporary Staging: Store each unioned/aggregated pass in its own Delta table.
- Pre-Merge Deduplication: Use
EXCEPT ALLbefore final merge to filter out redundancies.
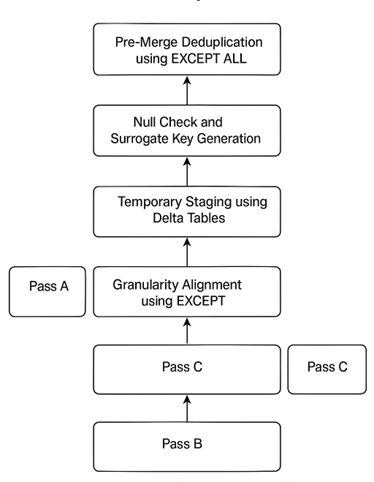
Figure 1: Optimzation null checks and multi-granularity deduplication in scalabal Spark-SQL piplines
4. Detailed Flow
4.1 Multi-Pass Handling
We categorize data passes into:
- Pass A: Raw records with base-level granularity
- Pass B: Aggregated data (e.g., PO, Vendor, Material)
- Pass C: Derived views with partial aggregations
Instead of merging directly, same-granularity passes are first aligned via UNION.
Example:
CREATE OR REPLACE TEMP VIEW unified_pass_A AS
SELECT * FROM pass_A_1
UNION
SELECT * FROM pass_A_2;
4.2 Staging and Surrogate Keys
CREATE TABLE temp_pass_A USING DELTA AS
SELECT * FROM unified_pass_A;
Apply surrogate key and null check:
CREATE OR REPLACE TEMP VIEW temp_pass_A_keys AS
SELECT *,
xxhash64(concat_ws('|', col1, col2, col3)) AS surrogate_key,
CASE WHEN col1 IS NULL THEN 1 ELSE 0 END AS flag_col1_null
FROM temp_pass_A;
4.3 Pre-Merge Deduplication
CREATE OR REPLACE TEMP VIEW final_to_merge AS
SELECT * FROM temp_pass_A_keys
EXCEPT ALL
SELECT * FROM already_existing_main_table;
Optionally, union with aggregated data:
CREATE OR REPLACE TEMP VIEW unified_merge_input AS
SELECT * FROM final_to_merge
UNION
SELECT * FROM temp_pass_B;
5. Key Benefits
| Optimization Lever | Before | After |
|---|---|---|
| Runtime | ~90 min | ~40 min |
| Shuffle Tasks | 2000+ | ~500 |
| Data Loss Risk | High | None |
| Debugging Complexity | High | Low |
6. Best Practices
- Union only same-granularity passes
- Use xxhash64 for performant surrogate keys
- Always deduplicate using EXCEPT ALL before final merge
- Avoid using window functions in large pipelines
- Separate aggregated and raw data flows
7. Conclusion
This modular architecture provides a scalable solution to null checks and deduplication in Spark SQL pipelines. By aligning granular passes, staging intermediate logic, and using EXCEPT ALL for deduplication, we reduce runtime, avoid data loss, and simplify pipeline management. This approach has proven effective in real-world production workloads involving billions of records.
— Abhishek Tyagi, Data & AI Engineer | Kritrim Intelligence


