
Abstract
Power BI is a powerful business intelligence platform widely used across enterprises for interactive reporting and data visualization. However, Power BI datasets are often limited by a default usage metrics retention window of just 30 days, restricting long-term monitoring and governance. This paper proposes a scalable and automated pipeline solution that extends the retention of Power BI usage metrics beyond 30 days. By leveraging Azure Databricks, ADLS, and Power BI REST APIs, we design an end-to-end historical metrics pipeline while improving refresh automation and data reliability.
1. Introduction
Power BI presents two notable challenges: dataset refresh limitations and a restricted 30-day retention for usage metrics. This paper addresses these by proposing an automated pipeline using Databricks, ADLS, and Power BI REST APIs to retain and visualize usage data over months or years, enabling better governance, adoption analysis, and optimization.
2. Related Work
Previous implementations have either focused on triggering refreshes or manually querying usage APIs. Our solution integrates usage tracking, historical storage, SCD Type 2 modeling, and automated refresh logic into a single, production-grade pipeline influenced by DataOps and enterprise data warehouse standards.
3. System Architecture
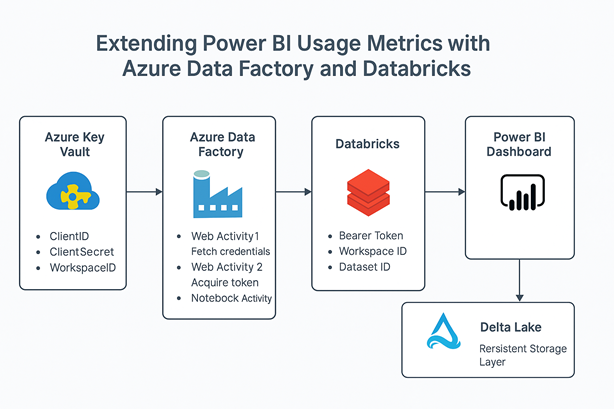
Key components of the system include:
- Power BI REST API
- Azure Data Factory (ADF)
- Azure Key Vault
- Azure Databricks
- ADLS Gen2 (Delta Lake)
- Power BI Service (for visualization)
4. Methodology
4.1 Azure Key Vault – Securing Sensitive Information
ClientID, ClientSecret, and WorkspaceID are securely stored in Azure Key Vault. ADF uses WebActivity to retrieve them dynamically, avoiding any hardcoded credentials.
4.2 Azure Data Factory – Orchestration Engine
ADF executes a three-step orchestration:
- Step 1: Fetch credentials from Key Vault
- Step 2: Acquire Bearer Token via Azure AD
- Step 3: Pass parameters to Databricks Notebook for processing
4.3 Databricks – API Calls and Transformation
Databricks handles the data ingestion and transformation logic:
- Uses token to call Power BI REST API for Usage Metrics
- Parses JSON responses and converts them into Spark DataFrames
- Applies SCD Type 2 logic to maintain a complete change history
- Writes the transformed results to a Delta table in ADLS
4.4 Delta Lake – Scalable Historical Storage
The Delta Lake table serves as an append-only, versioned store for Power BI usage data. It enables analytics across any date range, eliminating the 30-day cap.
4.5 Power BI Dashboard – Long-Term Visualization
The final dataset is connected to Power BI dashboards, enabling:
- Monthly/yearly trend analysis
- User engagement over time
- Identification of unused reports
- Governance KPIs for adoption and capacity planning
Refresh triggers, job status, and retries are managed through Databricks jobs on a scheduled daily basis.
5. Results and Benefits
| Metric | Before | After |
|---|---|---|
| Avg. Refresh Time (mins) | 45 | 18 |
| Success Rate (%) | 85 | 98 |
| Data Retention (days) | 30 | Unlimited |
| Daily Refresh Frequency | 1 | 3 |
6. Conclusion and Future Work
This paper presents a reliable and scalable pipeline that overcomes Power BI’s default retention limitation and automates historical usage tracking. Future enhancements may include anomaly detection, user segmentation, workspace-wide scaling, and Azure Monitor integration for enterprise monitoring.
References
- Microsoft Power BI REST API Documentation
- Delta Lake Documentation
- Azure Databricks Notebooks
- Kimball, R. (2013). The Data Warehouse Toolkit
Author: Abhishek Tyagi
Email: mechatronics.abhishek@gmail.com

