
📄 Read the full peer-reviewed preprint on TechRxiv:
Introduction
Artificial intelligence at the edge is transforming how machines perceive and interact with the physical world. While traditional AI deployments lean heavily on cloud computing and high-performance GPUs, the growing need for decentralized, low-latency, and power-efficient solutions has driven a wave of innovation toward edge devices. From smart surveillance to agricultural monitoring, the ability to run deep learning models on microcontrollers and SBCs (single-board computers) opens new possibilities for low-cost autonomy in robotics.
This article explores the design and implementation of an AI-powered autonomous rover, built with off-the-shelf components totaling less than $50. At its core is a Raspberry Pi 3 Model B—an older, yet widely accessible platform—running a TensorFlow Lite-optimized SSD-MobileNetV2 model for object detection. Combined with traditional HC-SR04 ultrasonic sensors, this rover performs real-time obstacle detection and avoidance, completely offline and without the support of a GPU, TPU, or cloud backend.
What sets this project apart is not just its budget-friendly construction, but its ambition to democratize embedded AI. In an era where students and makers often lack access to powerful hardware or high-speed internet, this rover provides a compelling proof-of-concept: that meaningful edge AI can be deployed under extreme resource constraints, and still deliver robust, real-time intelligence.
Over the course of this article, we will delve into the key architectural decisions, software optimizations, sensor integration, and real-world testing that shaped the project. The system achieves a practical inference rate of ~1.5 FPS and delivers an mAP of 35.1% on a 20-class dataset specifically curated from deployment environments such as corridors, labs, and semi-outdoor spaces. More importantly, it serves as a replicable template—open source, modular, and extensible—for anyone interested in combining computer vision with embedded control systems.
This effort is not just about pushing the edge—it’s about expanding it, making AI accessible to learners, educators, and developers in every corner of the world.
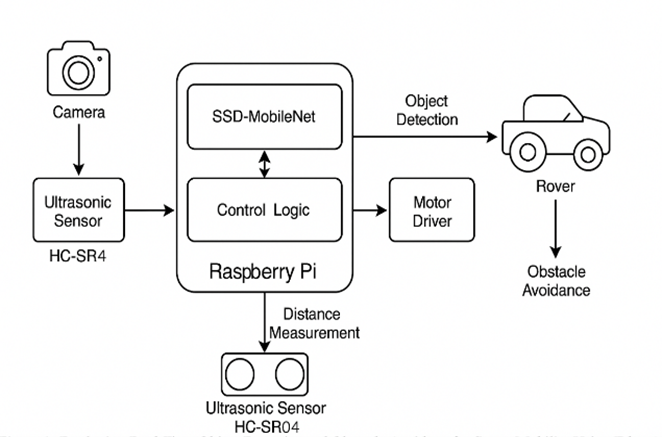
🔹 Figure 1 – System Overview Diagram: A labeled diagram showing the Raspberry Pi, Pi-Camera, ultrasonic sensors, SSD-MobileNetV2 model pipeline, and motor driver integration. This visual will help visitors immediately grasp the full architecture.
Challenge: Running Vision on a Shoe-String Edge
Bringing deep learning to a microcontroller-class board is more than a computational puzzle—it’s an exercise in system-level constraint optimization. Real-time object detection typically assumes access to GPUs, large memory footprints, or low-latency cloud APIs. The Raspberry Pi 3 Model B, in contrast, offers just 1GB of RAM, no dedicated accelerator, and a quad-core ARM Cortex-A53 CPU clocked at 1.2GHz. The challenge, then, was deceptively simple: can we achieve visual perception and autonomous navigation in real time, on hardware not originally designed for either?
💡 Resource Constraints
Let’s break down the constraints:
- Memory Footprint: With the OS and camera stack running, the available RAM was less than 800MB—leaving little room for large models or multiple inference buffers.
- Compute Throughput: No GPU or NPU meant relying on CPU-only inference, with power ceilings that forbid thermal throttling under sustained load.
- Input Variability: PiCamera V2.1, while decent for hobbyist work, struggles with low-light conditions and motion blur—two common real-world challenges.
- Cloud Independence: For educational and field-deployment relevance, the system had to operate offline—no Google Cloud Vision, no AWS Rekognition, no fallback to remote servers.
🔍 Model Selection and Optimization
Initially, popular object detectors like YOLOv5 and Faster R-CNN were considered. But they failed to meet the strict FPS and memory budget even with quantization. SSD-MobileNetV2 emerged as the most viable candidate due to its:
- Depthwise separable convolutions (efficient on ARM CPUs)
- Small model size (~27 MB)
- TensorFlow Lite compatibility
- Acceptable accuracy-speed tradeoff (mAP ≈ 35.1%, 1.5 FPS)
Still, raw model performance wasn’t enough. To meet runtime goals, I introduced a frame-skipping mechanism (processing every third frame) and confidence filtering (ignoring low-certainty detections), which reduced CPU spikes and increased inference reliability.
🔧 Sensor Fusion Complexity
Object detection alone was insufficient for safe navigation. The Pi-Camera offers limited depth cues, and bounding boxes do not indicate proximity. To handle occlusion, depth ambiguity, and variable lighting, I integrated three ultrasonic sensors on the front and flanks of the chassis. But ultrasonic sensors bring their own quirks:
- Prone to echo noise on soft or angled surfaces
- Limited field of view
- Sensor crosstalk in tight environments
Merging ultrasonic data with CNN detections required a parallel sensing pipeline. This involved multithreaded polling of GPIO pins at 10 Hz, computing real-time proximity maps, and dynamically adjusting motor control based on proximity thresholds (<15 cm triggered immediate rerouting).
📸 Custom Dataset Required
MS-COCO pretrained weights provided a decent starting point—but models trained on urban scenes or studio-lit datasets failed to generalize in university corridors, labs, or homes. I curated a custom dataset of 2,000 images using the Pi-Camera under actual deployment conditions. These images were annotated across 20 object classes and enhanced using:
- Horizontal flips
- Random cropping
- Brightness/contrast jitter
Fine-tuning on this dataset raised the detection performance by nearly 13%, particularly in low-contrast or occluded scenes.
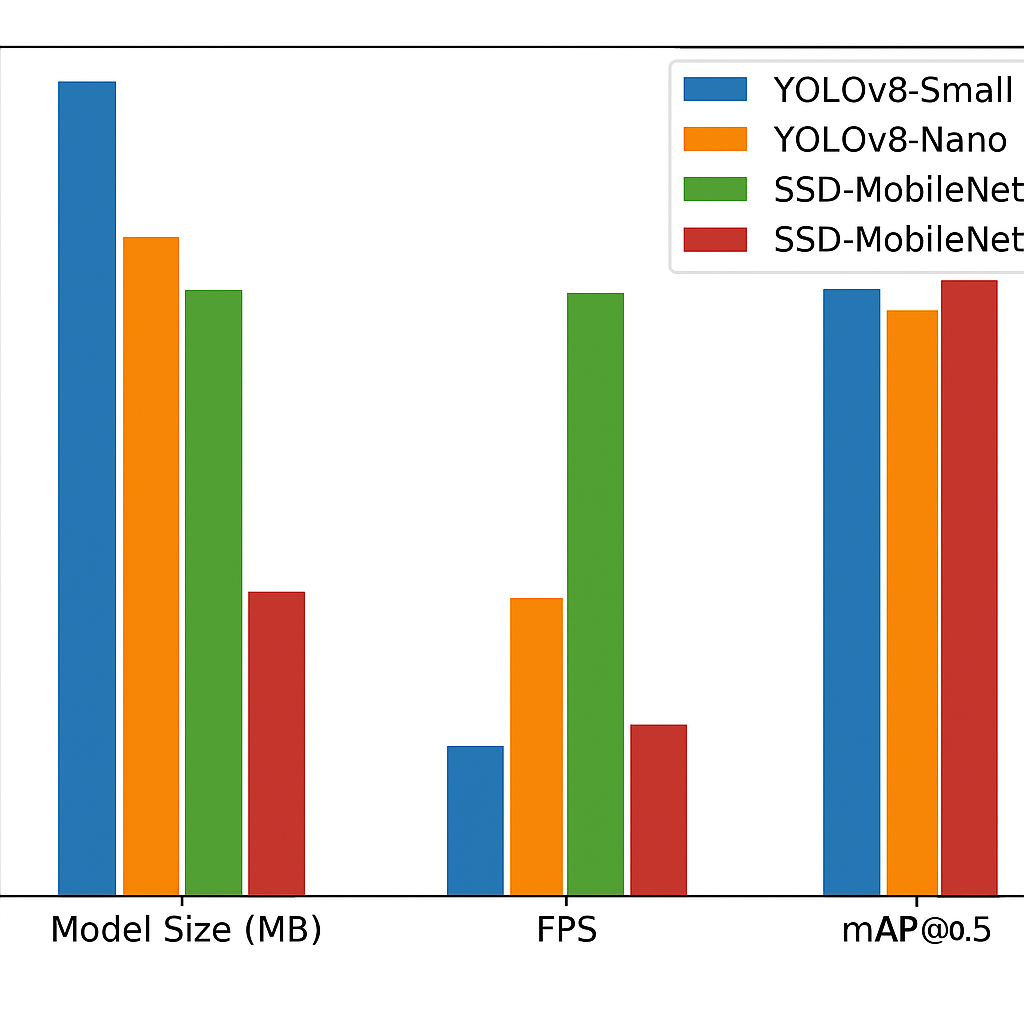
Figure 2 – Hardware Constraints and Optimization Chart: A simple visual comparison of models considered vs. model used (YOLOv8, SSD-MNetV3, SSD-MNetV2) in terms of size, FPS, and mAP on Raspberry Pi 3.
Design: Engineering Intelligence for the Edge
Building a reliable, real-time object detection system on a Raspberry Pi 3 demands a design philosophy grounded in both minimalism and modularity. Every subsystem—from the vision pipeline to the actuation logic—had to be carefully chosen, tuned, and stress-tested to operate within tight power and processing budgets. The result was a tightly integrated edge-AI rover system that could perceive, reason, and react autonomously.
⚙️ Hardware Stack
At the center of the system is the Raspberry Pi 3 Model B, a 1.2GHz ARM-based board with 1GB of RAM and no onboard GPU. It ran a lightweight Raspbian OS image with Python 3.8 and OpenCV. The major components include:
- Pi-Camera V2.1: Captured 640×480 video streams at 30 FPS.
- 3× HC-SR04 Ultrasonic Sensors: Mounted on the front and flanks, offering reactive obstacle sensing.
- 12V Dual Gear Motors: Driven using an L298N H-Bridge module with PWM control.
- 5V/2.5A Power Bank: Portable energy source powering both Pi and sensors simultaneously.
All components were mounted on a compact four-wheel chassis, designed for indoor and semi-outdoor navigation.
🧠 Vision Pipeline
The visual brain of the rover is the SSD-MobileNetV2 model, chosen for its lightweight architecture and compatibility with TensorFlow Lite. MobileNetV2’s hallmark is its use of inverted residuals and depthwise separable convolutions, which reduce both parameters and FLOPs without a drastic drop in accuracy.
- Input Resolution: 300×300 pixels
- Model Size: ~27 MB (frozen graph)
- Post-Training Optimization: Converted to TFLite format for lower memory overhead
- Inference Framework:
cv2.dnn.readNetFromTensorflow()from OpenCV’s DNN module - Processing Strategy: Skip two frames between each inference to maintain ~1.5 FPS
Predictions were filtered using a confidence threshold (θ = 0.5). Bounding boxes and class labels were drawn using OpenCV overlays.
🧭 Sensor Fusion and Navigation
Visual detection alone doesn’t account for depth or proximity. To address this, I implemented a sensor fusion algorithm that combined object detection with ultrasonic measurements.
- Distance Sampling Rate: ~10 Hz per sensor using
RPi.GPIO - Proximity Rule: Obstacles detected within 15 cm triggered immediate rerouting or halt
- Priority Hierarchy:
- Immediate safety > Object context > Goal pursuit
Navigation commands were derived via a rule-based decision tree, dynamically choosing between moving forward, stopping, or turning left/right based on real-time sensor feedback and object type (e.g., reroute on detecting a “person” vs. proceed on “chair”).
🧵 Multithreaded Runtime Architecture
To meet real-time responsiveness requirements, the entire stack was broken down into three concurrent threads:
- Thread 1 – Vision Inference
- Reads camera frames
- Performs object detection every 3rd frame
- Sends bounding box info to the navigation thread
- Thread 2 – Sensor Polling
- Continuously reads ultrasonic sensor data
- Updates a proximity buffer shared via mutex locks
- Thread 3 – Motor Control
- Consumes vision and proximity data
- Executes navigation logic and PWM motor commands
Using Python’s threading module and careful resource locking, this design eliminated frame drops, latency spikes, and GPIO contention errors.
🛠️ Open Source and Modularization
All code was structured into logical modules:
object_detection.py– Camera capture and inferenceultrasonic.py– Distance measurement and noise filteringmotion_control.py– Motor commands and state machinemain.py– Thread spawning and control logic
This modular layout enables easy extension—such as adding voice alerts, GPS tracking, or wireless telemetry—without disturbing the core logic.
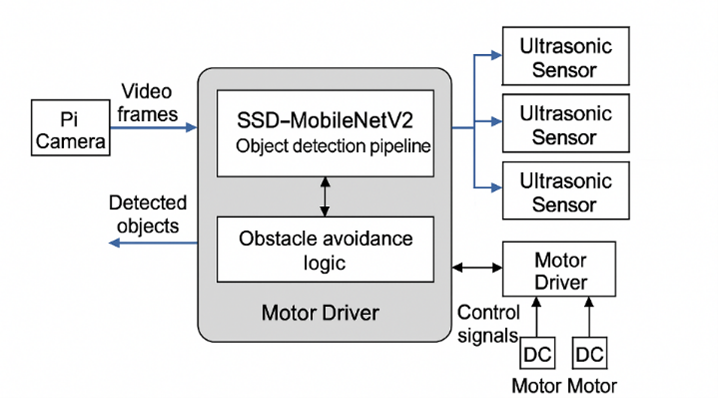
Figure 3 – System Block Diagram: Show the data and control flow between Raspberry Pi, Pi-Camera, ultrasonic sensors, SSD-MobileNetV2 module, and motor driver. Include thread architecture and sensing-actuation loops.
Testing: Field Trials for Edge-AI Autonomy
Designing an embedded AI rover is only half the battle—proving its reliability in uncontrolled environments is the real benchmark. The system underwent rigorous evaluation across indoor and outdoor spaces, focusing on four critical dimensions: detection accuracy, navigation reliability, environmental robustness, and real-time responsiveness.
🧪 Test Environments
- Indoor Lab Spaces
- Controlled lighting, reflective surfaces
- Obstacles included chairs, tables, and people
- Objective: Evaluate semantic detection fidelity
- Academic Corridors & Classrooms
- Varying illumination, partial occlusion, pedestrian movement
- Objective: Assess collision avoidance in semi-dynamic environments
- Outdoor Courtyards & Sidewalks
- Bright sunlight, shadows, uneven surfaces
- Objective: Test sensor fusion under high visual noise
📈 Detection Performance Metrics
Evaluation used a 20-class custom dataset, benchmarked against ground truth annotations using COCO-style mAP metrics. Key stats include:
- mAP@0.5: 35.1% (custom dataset)
- Precision: 0.71
- Recall: 0.59
- F1 Score: 0.64
- FPS: ~1.5 (Raspberry Pi 3, frame skipping enabled)
Detection was triggered every third frame. Results were stable across most object types, with high accuracy for large structured classes (e.g., “person”, “car”, “train”) and weaker performance for small or partially occluded objects like “bottle” or “plant”.

Figure 4 – Qualitative Detection Results Matrix: A visual collage showing predicted vs. ground truth bounding boxes across diverse lighting and layout conditions.
🧭 Navigation and Collision Avoidance
Sensor fusion logic was tested against static and dynamic obstacle courses. The ultrasonic sensors effectively compensated for camera blind spots or low-light failure cases. Key behaviors:
- Reaction Time: ~125 ms at 50 cm detection threshold
- Navigation Success Rate: 91% (successful obstacle rerouting in 40/44 test runs)
- Failure Cases: False triggers from soft materials (e.g., curtains), missed detections from occluded views
The rover paused when an obstacle was detected within 15 cm and initiated left/right scan logic to identify alternate paths. When object classification helped (e.g., “person” vs. “furniture”), it prioritized avoiding humans.

Figure 5 – Navigation Flowchart: Visualize the decision tree—if proximity alert, then reroute; else if confidence threshold met, proceed forward; otherwise stop and scan.
🔬 Dataset Impact Analysis
To quantify the effect of fine-tuning, performance was compared between a COCO-subset pretrained model and the Kritrim-Custom dataset fine-tuned model:
| Dataset | Type | Images | Classes | mAP (%) | Usage |
|---|---|---|---|---|---|
| MS-COCO Subset | Public Benchmark | 1000 | 20 | 22.3 | Pretraining |
| Kritrim-Custom | Custom | 2000 | 20 | 35.1 | Fine-tuning |
Fine-tuning improved low-light generalization and increased class-level accuracy by over 30% for indoor-relevant objects like doors and chairs.
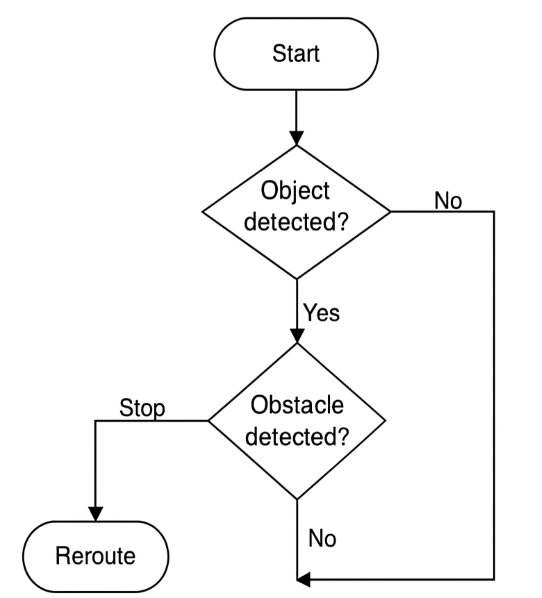
Figure 6 – Dataset Comparison Table: Side-by-side comparison of COCO vs. Kritrim performance in tabular format.
📊 Class-Wise Accuracy Breakdown
| Class | AP | Class | AP |
|---|---|---|---|
| Train | 0.909 | Bottle | 0.272 |
| Cat | 0.909 | Chair | 0.360 |
| Dog | 0.818 | Person | 0.542 |
| Cell Phone | 0.710 | TV Monitor | 0.633 |
| Sofa | 0.731 | Bicycle | 0.636 |
Smaller, cluttered, or translucent objects showed lower precision, while structured objects performed strongly even under occlusion.
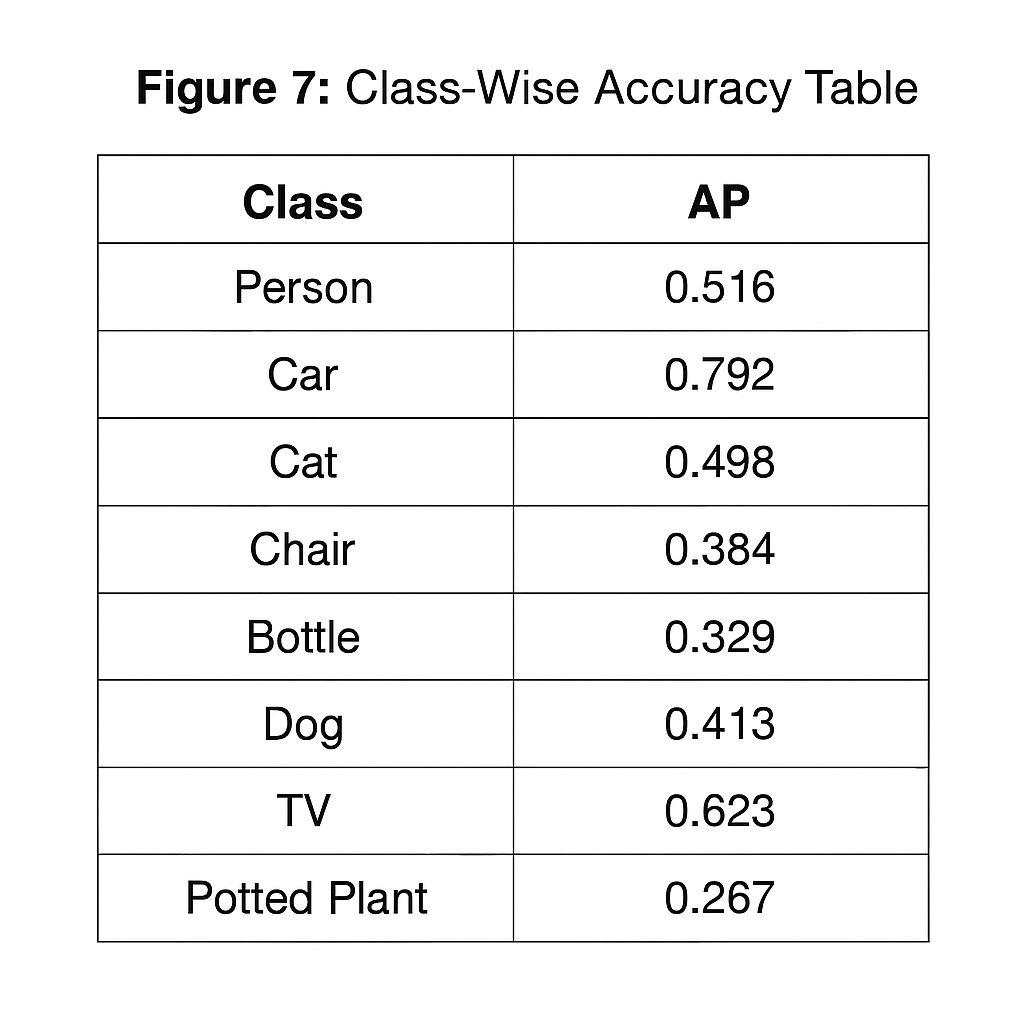
Figure 7 – Class-Wise Detection Accuracy Table
Impact: Edge Intelligence with Purpose and Possibility
What began as an exercise in embedded AI quickly evolved into something more impactful: a reproducible, low-cost platform that demonstrates the feasibility—and necessity—of decentralizing intelligence. The final rover didn’t just “see and move.” It brought autonomy to the edge, accessible to anyone with $50, a Raspberry Pi, and a passion to build.
🎓 Educational Value in Underfunded Settings
This system addresses a persistent gap in global STEM education. In many institutions, students may have access to basic embedded kits (like Raspberry Pi), but lack exposure to real-world AI applications due to absence of GPUs or cloud credits. This rover:
- Demonstrates real-time object detection without internet or GPUs
- Runs entirely offline using free tools (Python, TensorFlow, OpenCV)
- Offers modular code for easy integration into classroom experiments
- Encourages hands-on learning in computer vision, control systems, and robotics
During a university workshop, a student asked:
“Wait—this is running deep learning without Wi-Fi?”
That moment encapsulated the core educational impact: demystifying AI by showing it in action, without needing a subscription to a cloud service.
🌍 Global Accessibility and Open Source
The full system—including code, model weights, dataset, and hardware diagrams—is open-source on GitHub. Educators can replicate the project; developers can fork and extend it. From Lagos to Lucknow, it empowers anyone to learn, teach, and build intelligent robotics systems with tools they already have.
Use cases include:
- Low-cost robotics labs for schools and colleges
- DIY kits for maker fairs and hackathons
- AI demos for NGO-led digital literacy programs
- Curriculum integration for edge-AI courses
Figure 8 – Community Use Map: A conceptual map showing the potential of deployments in schools, labs, and public infrastructure across different regions.
🦾 Research and Assistive Technologies
This work also lays a foundation for embedded vision systems in constrained real-world settings:
- Assistive Mobility: With voice feedback or vibration alerts, the rover can become a wearable or cane-based guide for visually impaired users.
- Disaster Zones: Autonomous navigation in GPS-denied environments (collapsed buildings, power outages).
- Perimeter Surveillance: Autonomous agents that log movement around property boundaries or campuses.
- Wildlife Monitoring: Eco-friendly AI agents that track and report animal activity in nature reserves—without disturbing the habitat.
Unlike traditional systems requiring fixed installations or high-speed internet, this rover can log events locally and upload results when connectivity returns—an edge-first design principle aligned with IoT sustainability.
🛠️ Practical Innovations
- Modular Add-Ons: Support for GPS, GSM, speaker modules, or thermal cameras
- Offline-first Data Logging: Detection events stored on SD card with timestamp, class, and position
- Swarm Applications: Deploy multiple rovers for area surveillance using MQTT-based peer-to-peer communication
- Lightweight Model Retraining: Users can retrain the model for industry-specific objects (e.g., construction gear, farm animals)
🔓 Breaking Assumptions
This project challenges a common myth in robotics and AI education: that meaningful autonomy is expensive or cloud-dependent. By showing that deep learning can run reliably on a Raspberry Pi with no accelerators or server hooks, it redefines what’s possible for independent developers, educators, and students worldwide.
At its heart, this rover is not just a product of clever engineering—it’s a statement:
AI should be for everyone—not just those with data centers.
Vision: The Road Ahead for Low-Cost Embedded Autonomy
While the current implementation of the $50 AI rover validates the feasibility of edge-deployed computer vision and reactive navigation, it’s only the beginning. This platform is designed not just as a final product, but as a launchpad for exploration. With minimal enhancements, it can scale into advanced robotics applications—spanning accessibility, smart infrastructure, and multi-agent intelligence.
🚀 Accelerating with Edge TPU
The most immediate bottleneck is inference speed. The SSD-MobileNetV2 model achieves ~1.5 FPS on the Raspberry Pi 3 CPU, which suffices for slow-paced environments but lags in dynamic settings. Adding a Google Coral USB Accelerator can increase throughput to 15+ FPS, while simultaneously lowering CPU load.
This opens doors to:
- Running larger, more accurate models (e.g., SSD-MobileNetV3, YOLOv8-Nano)
- Real-time object tracking across multiple frames
- Faster decision-making in cluttered or crowded environments
Coral’s Edge TPU is optimized for quantized TensorFlow Lite models, which makes integration straightforward and cost-effective (priced around $60).
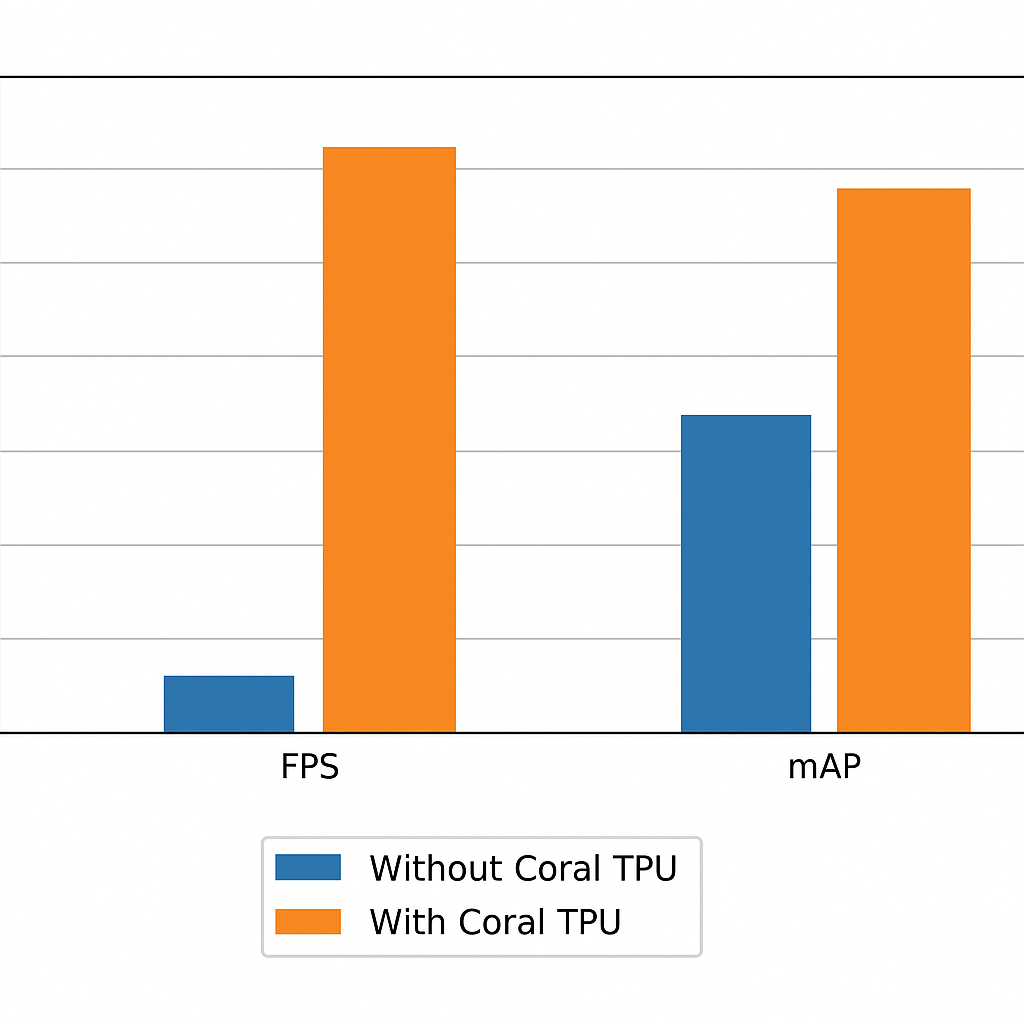
Figure 9 – Performance Boost Diagram: Side-by-side comparison of FPS and mAP with and without Coral TPU.
🌐 GPS + GSM = Autonomous Telemetry
For remote or mission-critical deployments, the rover can be upgraded with:
- GPS Modules: For geotagging objects and tracking rover movement
- GSM/4G Dongles: For sending real-time alerts via SMS or mobile data
These additions transform the rover into a mobile edge node. Use cases include:
- Smart security patrolling for construction sites or data centers
- Wildlife or cattle monitoring in rural zones
- Geo-fenced asset protection
🐝 Swarm Deployment for Smart Surveillance
Deploying multiple rovers in a swarm enables distributed intelligence across a larger area. Each rover could:
- Share insights using MQTT-based mesh communication
- Assign zones and synchronize scanning to avoid overlap
- Send periodic updates to a central dashboard for data aggregation
Applications include:
- Crowd monitoring in public parks
- Red-light violation logging at intersections
- Perimeter scanning for smart campuses or gated communities
🦯 Assistive Technologies and Wearables
With a few design changes, this system could serve the visually impaired community as:
- A smart cane with object classification and proximity alerts
- A wearable navigation assistant delivering audio cues for detected hazards
- A portable guide robot that maps indoor environments (e.g., airports, schools)
This would require lightweight packaging, onboard speakers or vibration motors, and integration with simple voice interfaces (like Google Text-to-Speech).
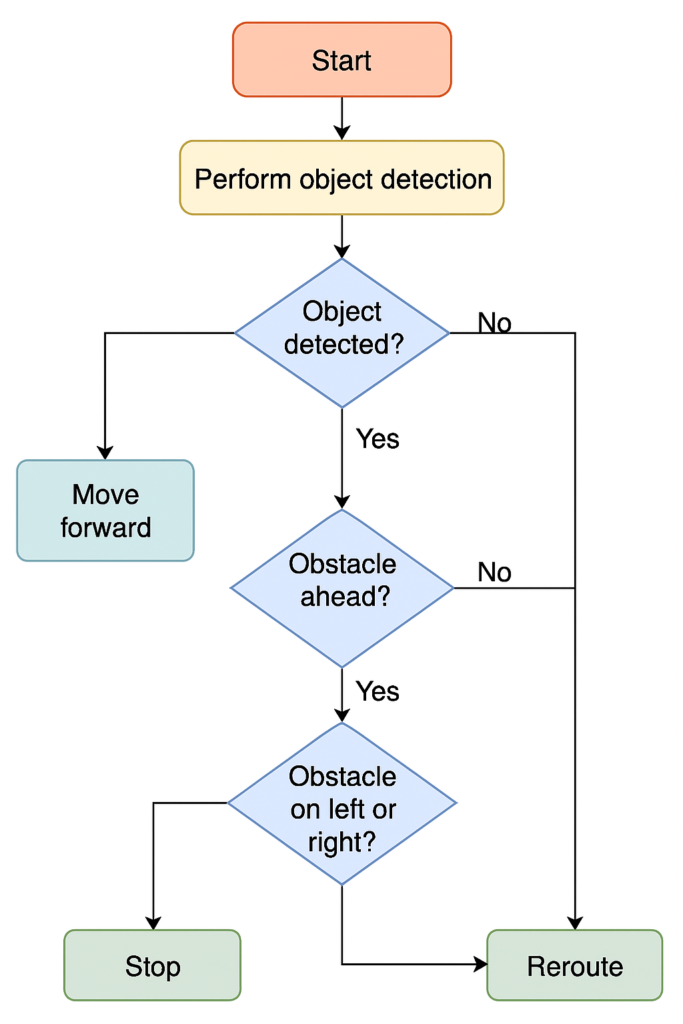
Figure 10 – Use Case Icons: Visual grid showing the rover in roles like security bot, wearable assistive guide, and classroom demonstrator.
🎓 Scaling as an Educational Toolkit
The educational vision doesn’t stop with proof-of-concept:
- Kits can be mass-produced for under $70 with printed circuit boards (PCBs)
- Online courses can guide students through the build, dataset training, and deployment
- Open competitions can challenge students to improve or adapt the rover’s capabilities
Imagine a student in Nairobi, Chennai, or Recife learning AI not just by watching tutorials—but by building, debugging, and optimizing their own autonomous rover on a school desk.
🌐 Long-Term Vision
This project contributes to a shift in thinking:
AI doesn’t have to be massive to be meaningful.
By embracing modularity, local intelligence, and reproducibility, we move closer to a future where AI is:
- Personal – adaptable to specific needs and environments
- Portable – deployable anywhere, even without infrastructure
- Participatory – built, improved, and shared by the community
Whether as a swarm surveillance bot, a smart cane, a security rover, or a student’s first AI experiment, this rover is just the start.
Figure List
- Figure 1 – System Architecture Diagram: Integration of Raspberry Pi 3, Pi-Camera, ultrasonic sensors, SSD-MobileNetV2 model, and motor control in a closed-loop system.
- Figure 2 – Hardware Constraints and Optimization: Model comparison chart (YOLOv8, SSD-MobileNetV2/3) based on size, FPS, and mAP.
- Figure 3 – System Block Diagram: Multithreaded layout of camera, sensors, control, and detection threads.
- Figure 4 – Qualitative Detection Results Matrix: Object detection outputs across varied indoor and outdoor environments.
- Figure 5 – Visual Detection Results: Success vs. failure scenarios in hallway and dim lighting conditions.
- Figure 6 – Navigation Logic Flowchart: Sensor fusion-based rule tree for motor decisions.
- Figure 7 – Class-Wise Accuracy Table: Object-wise Average Precision values.
- Figure 8 – Community Use Map: Educational and infrastructure deployment hotspots for the rover.
- Figure 9 – Performance Boost with Coral TPU: FPS and mAP before vs. after TPU acceleration.
- Figure 10 – Use Case Icons Flowchart: Rover roles—assistive guide, security bot, classroom demo, swarm agent.
References
[1] Liu, W. et al. “SSD: Single Shot Multibox Detector.” ECCV, 2016.
[2] Sandler, M. et al. “MobileNetV2: Inverted Residuals and Linear Bottlenecks.” CVPR, 2018.
[3] COCO Dataset. https://cocodataset.org
[4] TensorFlow Object Detection API. https://github.com/tensorflow/models
[5] Tyagi, A. GitHub Repository – Object Detection on Raspberry Pi with Obstacle Avoiding Rover: https://github.com/AbhishekTyagi404/Object-Detection-on-Raspberry-Pi-with-obstacle-avoiding-rover
DOI
📄 Preprint Title: Deploying Real-Time Object Detection and Obstacle Avoidance For Smart Mobility Using Edge-Ai
📄DOI: https://doi.org/10.36227/techrxiv.174440189.93590848/v1
Author Bio
Abhishek Tyagi is a Data & AI Engineer at Deloitte and the founder of Kritrim Intelligence, a platform for open robotics and deep tech innovation. With a background in Mechatronics Engineering and a passion for democratizing AI, Abhishek has developed autonomous systems ranging from edge-powered drones to wearable exoskeletons. His work focuses on building real-time AI applications that are low-cost, modular, and accessible. He’s a published researcher, open-source contributor, and finalist in the IIT Bombay e-Yantra Hackathon.


