
Introduction-
- CNNs are similar to typical neural networks.
- CNN takes images as inputs.
- This allows us to solve problems involving Image Recognition, Object Detection, & Computer vision applications.
Introduction
Convolutional Neural Networks (CNNs) are a type of neural network that are similar to traditional neural networks but are specifically designed for tasks involving image data. CNNs are primarily used to address problems related to image recognition, object detection, and computer vision applications.
A Convolutional Neural Network (CNN) is a deep learning algorithm where operations are performed differently from typical matrix-based neural networks. Instead of using matrix operations directly, CNNs rely on a mathematical operation called convolution.
In mathematics, convolution can be defined as the integral of the product of two functions, which produces a third function after one of the functions is reversed and shifted to perform the desired operation. This mathematical operation allows CNNs to effectively process and analyze image data.
CNNs are inspired by the biological neural networks of animals, specifically the visual cortex, which processes visual information. CNNs are also effective in real-time image recognition and video classification, requiring fewer data than other algorithmic approaches.
The design of a CNN typically consists of an input layer, an output layer, and multiple hidden layers in between. These layers work together to classify the input image. Like traditional neural networks, CNNs are made up of neurons with learnable weights and biases. Each neuron receives input, performs a dot product, and applies non-linearity.
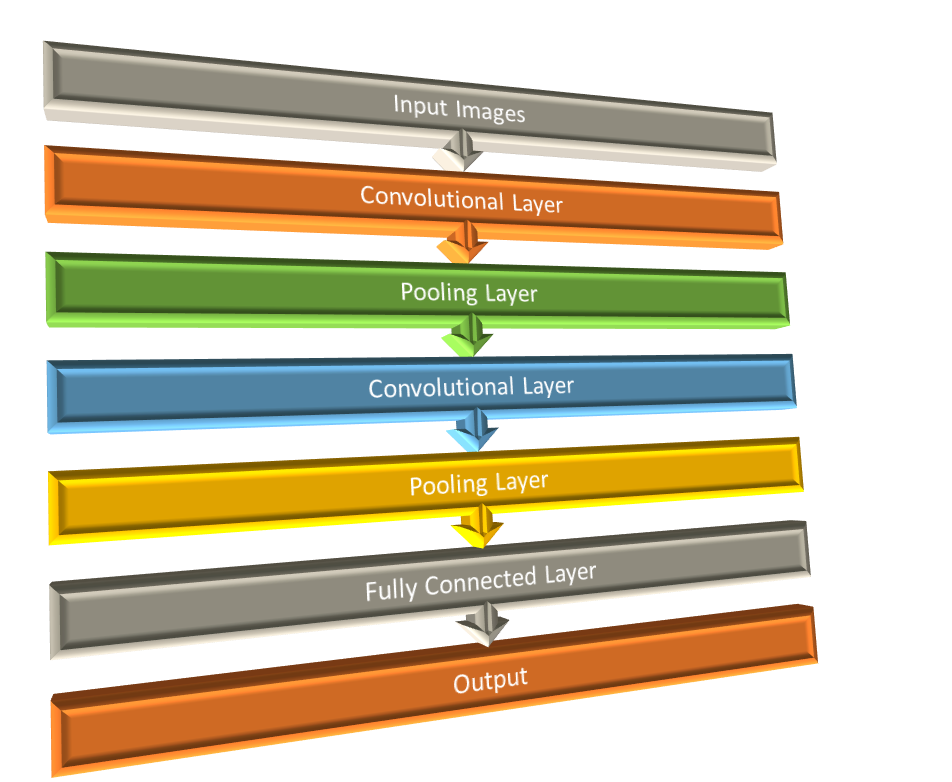
The architecture of CNNs generally includes an input image, convolutional layers, pooling layers, and a fully connected layer that leads to the penultimate output. The entire network is optimized to express a single differential score function. Additionally, loss functions like SoftMax or SVM can be used on the fully connected layers. Filters are applied in each layer of the CNN, further enhancing the network’s ability to learn complex features from the data.
CNNs Architecture –
The hidden layers of a Convolutional Neural Network (CNN) typically consist of a series of convolutional layers that operate by convolving, often using multiplication or the dot product.
Let’s take an image, for example, with only the Red channel, and calculate its convolutional layer dot product through simple mathematics. We can use a 2×2 filter and start with an empty matrix. To obtain the output in the form of a matrix, we slide the 2×2 filter matrix across the Red channel matrix from left to right. As we move the filter, we compute the dot product and the overlapping pixel values, placing the result into the output matrix, as shown in the figure below.
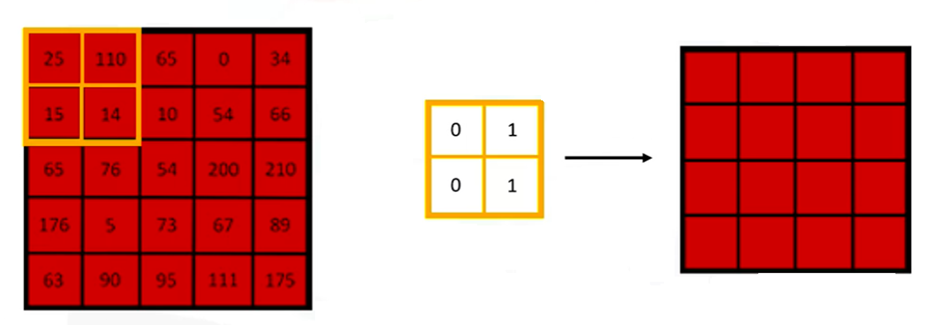
We repeat the process by shifting the filter one cell (or a stride) at a time and inserting the result into the output matrix. This continues until we cover the entire image, after which the result is sorted in the output matrix. We then repeat this process for the Green and Blue channels to get the 3D channel matrix as the output. We can use one or more filters in the convolutional layers to achieve the desired results. The more filters we use, the better we can preserve the spatial dimensions.
In addition to the convolutional layers, CNNs also employ Rectified Linear Units (ReLU) that filter the convolutional steps. ReLU functions pass only positive values to the output and convert negative values to zero.
The activation function commonly used in CNNs is the ReLU function, along with fully connected layers and normalization layers. These layers are often referred to as hidden layers because their inputs and outputs are determined by the activation function and the final convolutional step.
ReLU (Rectified Linear Unit)–
ReLU, also known as Rectified Linear Unit, is an activation function used in the context of Artificial Neural Networks (ANN). It is defined as the positive part of its argument. The function can be written as:
F(x)=max(0,x)
F(x) = x+
Where x is the input to the neuron. Essentially, if the input is positive, it passes through unchanged, and if it is negative, it is set to zero. This helps introduce non-linearity into the network, allowing it to learn complex patterns.
Pooling Layer
The next layer in the network is the pooling layer. The primary purpose of the pooling layer is to reduce the dimensionality of the data as it propagates through the network. This reduction helps to decrease the computational load and also makes the network more robust to variations in the input. There are two main types of pooling layers used in CNNs:
- Max-Pooling: In max-pooling, for each section of the image that is scanned, we retain only the highest value from the matrix. This helps capture the most prominent features in the image.
- Average-Pooling: In average-pooling, we scan the image for each section and calculate the average value of the elements in the scanning area. This results in a more generalized output, smoothing out the features.
Fully Connected Layer
At the penultimate stage of the CNN, which is known as the fully connected layer, we flatten the output from the previous layers. Every node in the current layer is connected to every node in the next layer. This layer takes the output from the preceding layers, whether they are convolutional or pooling layers, and processes it for the final classification or regression task. The fully connected layer ensures that the network can learn complex relationships between the features extracted from the input data.


